


Robots.txt é um arquivo de texto que fica hospedado na raiz do site e apresenta instruções aos robôs dos buscadores, como o Google. No arquivo robots.txt, é possível indicar quais diretórios não devem ser rastreados, arquivos que não devem ser indexados e onde estão os Sitemaps, por exemplo.
Você já assistiu ao filme “Eu, Robô”?
No filme estrelado por Will Smith, estamos no ano de 2035, os robôs existem para servir os humanos e devem seguir 3 regras:
- Os robôs não podem machucar os humanos;
- Os robôs devem obedecer os humanos (caso não vá contra a primeira regra);
- Os robôs devem proteger a si mesmos (caso não vá contra a primeira e a segunda regra).

Ainda não estamos em 2035, mas a internet já é cheia de robôs, preenchendo formulários, estragando os relatórios do Google Analytics, hackeando computadores e indexando conteúdos nos buscadores da internet.
O robô do Google, carinhosamente chamado de “Googlebot”, mas também conhecido como “Crawler”, “Spider” ou simplesmente “Bot”, foi criado para vasculhar toda a web em busca de novas páginas (ou atualizações) para indexar nos resultados de busca do Google.
Eles iniciam inicia sua busca por uma lista de URLs previamente indexada, e seguem para outras páginas por meio dos links existentes, identificando atualizações e novos conteúdos e mantendo a página de resultados do Google sempre atualizada e relevante para os usuários.
Para entender melhor todo o processo de indexação das páginas no Google (inclusive o que é indexação), acesse o post Como o Google funciona.
Os outros buscadores, como Bing e Yahoo, também possuem seus próprios robôs, que trabalham de forma semelhante.
E assim os robôs vão de página em página, por meio dos links, enviando uma quantidade astronômica de conteúdos para indexação (para ter uma idéia, hoje temos mais de 1 bilhão e meio de sites na internet).

Mas e se eu não quiser que os robôs rastreiem minhas pastas, imagens ou determinados recursos? Aí entra o arquivo robots.txt.
Índice
3 motivos para usar um arquivo robots.txt no seu site
1. Evitar o rastreamento de páginas internas, arquivos e recursos
2. O tempo dos robôs no seu site é limitado
3. Você pode usar para indicar onde estão seus sitemaps
E quando NÂO usar o arquivo robots.txt?
Disallow e Allow (cada regra precisa ter ao menos um)
Como criar e testar o arquivo robots.txt
O que é robots.txt?
Em resumo, o robots.txt é um arquivo de texto publicado na raiz do site que contém diretrizes para os robôs dos mecanismos de buscas, principalmente para evitar a sobrecarga do site com solicitações.
Lembra das 3 regras que os robôs do filme deveriam seguir, lá no começo do post? Se elas estivessem em um arquivo robots.txt, por exemplo, o documento de texto ficaria mais ou menos assim:
User-agent: * Disallow: /machucar-humanos/ Disallow: /desobedecer-humanos/ Allow: /desobedecer-humanos/proteger-humanos/ Disallow: /nao-se-proteger/ Allow:/nao-se-proteger/obedecer-humanos/ Allow:/nao-se-proteger/proteger-humanos/
Basicamente, estamos dizendo que a regra se aplica para todos os robôs (User-agent) e listando o que os robôs devem desconsiderar (Disallow) e as exceções às regras (Allow). Por exemplo: ele pode desobedecer um humano para o proteger, ou ele pode não se proteger para obedecer um humano.
Inclusive um erro muito comum é sites que são lançados e o arquivo robots.txt não é revisado. Passam dias, semanas e até meses e nada do site aparecer, nem quando se busca pelo nome da empresa.
O problema é que geralmente os programadores configuram o robots.txt da seguinte maneira enquanto o site está sendo desenvolvido:
User-agent: * Disallow: /
Assim, o arquivo está dizendo para todos os robôs (User-agent: *) que não rastreiem nenhuma página do site (Disallow: /). Se após o lançamento do site o arquivo não for corrigido, as diretrizes permanecerão as mesmas.
Para saber mais, confira a documentação do Google sobre robots.txt.
3 motivos para usar um arquivo robots.txt no seu site
Talvez agora você esteja se perguntando: “mas por que diabos eu vou dizer para o robô do Google para desconsiderar recursos do meu site, se quanto mais meu site aparecer lá, mais tráfego orgânico vou receber?”
Bom, você não está errado. Apesar de seu uso ser considerado uma boa prática de SEO, a maioria dos sites não precisa de um robots.txt. O próprio Google afirma isso nas suas diretrizes. Caso o site não possua um arquivo com as diretrizes para os robôs, ele será rastreado e indexado normalmente.
Além de evitar a sobrecarga do site com solicitações, temos 3 motivos para você incluir as regras no seu site:
1. Evitar o rastreamento de áreas internas, arquivos e recursos
Geralmente um site tem uma área de login, páginas de uso interno ou uma área ainda em desenvolvimento, por exemplo.
Esses tipos de páginas podem, e devem, ter regras para não serem rastreadas por robôs. Também é possível impedir que tipos de arquivos (como PDF ou DOC), imagens e até recursos, como Ajax, sejam rastreados.
Se você faz Inbound Marketing, é uma ótima funcionalidade, caso hospede seus materiais dentro do seu domínio. Afinal, você quer que seus potenciais Leads encontrem sua Landing Page e convertam, e não encontrem e acessem diretamente o material final, correto?
Usando as regras de um arquivo de robots.txt, você pode impedir o rastreamento de uma área inteira do seu site e ainda novas regras para dizer quais páginas são exceções e que devem ser indexadas.
2. O tempo dos robôs no seu site é limitado
Não sei se você sabe, mas o Google já declarou oficialmente que tem um limite de rastreamento, o famoso “Crawl Budget”.
Isso quer dizer que, caso você não determine quais páginas o Google não deve rastrear, ele pode perder mais tempo no seu site rastreando páginas sem valor e deixar de rastrear as páginas que você realmente gostaria de indexar ou atualizar.
Se você estiver com dificuldades para os robôs rastrearem e indexarem todo o seu site, pode ser que o problema realmente se trata de Crawl Budget. Blloquear o rastreamento de páginas irrelevantes pode resolver.
Lembrando que, geralmente, isso só se torna realmente um problema para grandes sites e portais de conteúdo, com muitas páginas.
3. Você pode usar para indicar onde estão seus sitemaps
É uma funcionalidade simples, mas que ajuda ao Google e aos outros buscadores a encontrarem seus sitemaps e consequentemente entenderem a organização do seu site.
Quer saber mais sobre Sitemaps? Acesse o post Sitemap XML: tudo o que você precisa saber.
Na dúvida se seu site possui ou não um arquivo robots.txt? Faça o teste: acesse o endereço principal do seu site e inclua /robots.txt no final. Por exemplo: https://resultadosdigitais.com.br/robots.txt
Use as funcionalidades de SEO do RD Station Marketing para aumentar seu tráfego orgânico
O RD Station Marketing é a melhor ferramenta para automação de Marketing Digital tudo-em-um para sua empresa. Ele tem funcionalidades de SEO como o Painel de Palavras-Chave da Semrush, além de fazer uma análise do seu site! Faça um teste gratuito de 10 dias.
- Ao preencher o formulário, concordo * em receber comunicações de acordo com meus interesses.
- Ao informar meus dados, eu concordo com a Política de privacidade.
* Você pode alterar suas permissões de comunicação a qualquer tempo.
E quando não usar o arquivo robots.txt?
Você chegou a testar se seu site já possui um robots.txt? Então você viu como é fácil acessá-lo… Assim, outros usuários, inclusive hackers, também encontram com facilidade.
Por isso, não é interessante utilizar o arquivo para bloquear o acesso a documentos pessoais ou arquivos confidenciais, pois você está bloqueando nos mecanismos de busca, mas está facilitando o acesso diretamente pelo robots.txt.
Nesse caso, a solução mais recomendada é incluir uma senha para o acesso ou utilizar a Meta Tag Robots.
Importante: ter páginas listadas no arquivo para não serem rastreadas não garante que elas não sejam exibidas no Google. Isso funciona para bloquear o acesso a arquivos e recursos, mas para garantir que páginas não serão exibidas nos resultados, a melhor forma é usar Robots Meta Tag Noindex.
Robots.txt x Meta Tag Robots
Diferente do arquivo robots.txt, que é para todo o site, a Meta Tag Robots permite que você configure páginas individualmente e indique aos buscadores para não indexarem a página e/ou não sigam os links presentes na página.
A tag é inserida dentro da seção <head> no HTML da página e possui a seguinte estrutura:
- Para indicar que os robôs não devem indexar a página:
<meta name="robots" content="noindex" />
- Para indicar que os robôs não devem seguir nenhum link presente na página:
<meta name="robots" content="nofollow" />
- Para indicar aos robôs que não indexem a página nem sigam seus links:
<meta name="robots" content="noindex, nofollow">
Esta é a melhor alternativa para garantir que determinadas páginas não sejam indexadas nos buscadores. Caso a página já tenha sido indexada e a meta tag foi inserida após isso, quando os robôs rastrearem a página novamente, a tag será lida e o comando para não indexar será enviado aos servidores.
Se você usa Wordpress e tem o plugin Yoast SEO instalado, nas configurações do plugin em cada página ou post é possível incluir essas configurações:
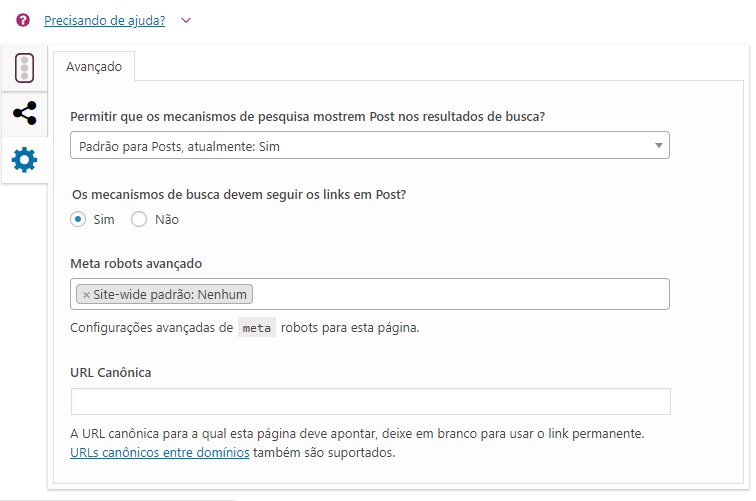
Um exemplo comum de uso da Meta Tag Robots é nas Thank You Pages. Como são as páginas que disponibilizamos os materiais, o ideal é elas não indexarem nos buscadores, somente as Landing Pages.
Também não é uma boa prática incluir as URLs delas no arquivo robots.txt, pois além de não garantir que elas não serão indexadas, ainda vai revelar para qualquer usuário os endereços das Thank You Pages.
Usar a Meta Tag Robots Noindex Nofollow em cada uma das minhas Thank You Pages garante que elas não serão indexadas pelos buscadores e ainda indica que os links presentes nela não sejam seguidos, o que também impede que os materiais sejam indexados e exibidos nos resultados de busca.
Desta forma você garante que somente as Landing Pages sejam indexadas nos buscadores.
Para saber mais sobre o assunto, confira a documentação do Google sobre Meta Tag Robots.
Sintaxe
Para os robôs interpretarem o conteúdo do arquivo, é necessário que o robots.txt siga alguns padrões.
O primeiro deles é que precisa ser um arquivo de texto ASCII ou UTF-8. As regras inseridas no arquivo são interpretadas de cima para baixo, sendo que a sequência é: user-agent (para quem a regra se aplica) e quais arquivos e diretórios esse robô pode ou não acessar.
Outro ponto importante é que as regras diferenciam maiúsculas e minúsculas. Portanto, se incluir um diretório “/exemplo” e também tiver “/Exemplo”, a regra só vai se aplicar para o que foi incluído no arquivo.
Confira a seguir as diretivas usadas nos arquivos:
User-agent (obrigatório)
É onde indicamos para qual robô a regra a seguir será aplicada e por padrão é a primeira linha de qualquer regra. Nesta lista é possível encontrar a maioria dos robôs existentes na internet e caso a regra se aplique para todos os robôs, é só incluir um * no local, como no exemplo abaixo:
User-agent: *
Disallow e Allow (cada regra precisa ter ao menos um)
Disallow é a diretiva que determinado diretório ou página não deve ser rastreado no site, já Allow é o oposto, indicando quais diretórios e páginas devem ser rastreados.
Por padrão, os robôs já rastreiam todas as páginas do site, sem necessidade de incluir Allow no arquivo. É necessário usar apenas em casos que uma determinada seção ou grupo é bloqueado (Disallow), porém dentro deste grupo existem exceções que podem ser rastreadas, por exemplo:
User-agent: * Disallow: /arquivos/ Allow: /arquivos/seo/
No exemplo acima, a regra se aplica à todos os robôs, sendo que todo o diretório “/arquivos/” não deve ser rastreado, exceto o subdiretório “/seo/”.
Sitemap (opcional)
É a indicação de onde fica o sitemap e é uma boa prática para auxiliar o Google no rastreamento e indexação do site. Por exemplo:
User-agent: * Disallow: /arquivos/ Allow: /arquivos/seo/ Sitemap: https://site.com/sitemap.xml
Simples até aqui, né?
Mas a sintaxe de arquivos robots.txt possui muitas variações e diversos casos de uso. Para se aprofundar um pouco mais, recomendo conferir a sintaxe completa de robots.txt.
Chega de teoria, vamos para a prática!

Como criar e testar o arquivo robots.txt
Como o próprio nome já diz, para criar um arquivo robots.txt você só precisa de um editor de textos simples, como o bloco de notas do computador.
Importante: o nome do arquivo obrigatoriamente é “robots.txt” e precisa estar instalado na raiz do site (site.com/robots.txt).
Para facilitar a sua compreensão, é possível incluir anotações no arquivo, iniciando suas linhas com #. Por exemplo:
# Bloquear o rastreamento de JPGs pelo Google User-agent: Googlebot Disallow: /*.jpg$
Criou o arquivo de texto com as regras que quer aplicar no seu site? Antes de enviar ao Google, é importante testar se está tudo certo. Basta acessar a ferramenta de teste de robots.txt do Google, presente dentro do Google Search Console.
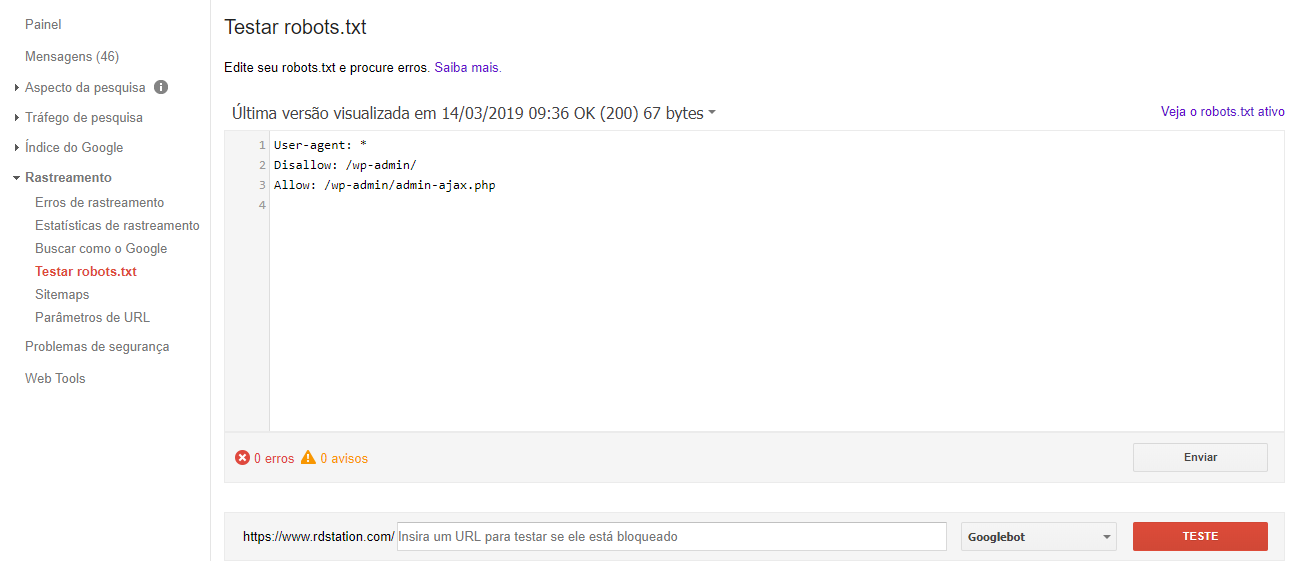
Com a ferramenta é possível testar se determinadas páginas ou recursos estão sendo bloqueados pelo arquivo, além de verificar possíveis erros no arquivo. As atualizações podem ser feitas diretamente na ferramenta de testes, que permite o download do arquivo para atualizá-lo no servidor do seu site.
Tudo certo com seu arquivo robots.txt? Agora sim é hora de atualizar o Google sobre ele. Na própria ferramenta de testes, existe um botão “Enviar”, que atualiza e notifica o Google sobre as mudanças realizadas.
10 exemplos de robots.txt
Para você se inspirar e aprender na prática, confira 10 exemplos reais de arquivos robots.txt:
- 1. https://facebook.com/robots.txt (longo e configurado para vários user-agents)
- 2. https://instagram.com/robots.txt (tem até o user-agent do DuckDuckGo)
- 3. https://www.apple.com/robots.txt (destaque para as regras para o Baidu)
- 4. https://www.google.com.br/robots.txt
- 5. https://www.youtube.com/robots.txt
- 6. https://www.estadao.com.br/robots.txt
- 7. https://www.globo.com/robots.txt
- 8. https://www.dell.com/robots.txt
- 9. https://www.cocacola.com.br/robots.txt
- 10. https://www.amazon.com.br/robots.txt
Assim como conseguimos acessar e conferir como é o arquivo robots.txt de cada uma das empresas acima, você pode ver como é o arquivo de qualquer site que faz uso dele, basta acessar o site e incluir /robots.txt no final do endereço. Partiu dar uma olhada na concorrência?
Ainda tem alguma dúvida sobre robots.txt? Comente abaixo ou acesse a página do Google de perguntas frequentes.
Baixte também o nosso Guia Completo do SEO. É gratuito, basta preencher os dados abaixo!


